5.11. Performing out-of-core computations on large arrays with Dask
 This is one of the 100+ free recipes of the IPython Cookbook, Second Edition, by Cyrille Rossant, a guide to numerical computing and data science in the Jupyter Notebook. The ebook and printed book are available for purchase at Packt Publishing.
This is one of the 100+ free recipes of the IPython Cookbook, Second Edition, by Cyrille Rossant, a guide to numerical computing and data science in the Jupyter Notebook. The ebook and printed book are available for purchase at Packt Publishing.
▶ Text on GitHub with a CC-BY-NC-ND license
▶ Code on GitHub with a MIT license
▶ Go to Chapter 5 : High-Performance Computing
▶ Get the Jupyter notebook
Dask is a parallel computing library that offers not only a general framework for distributing complex computations on many nodes, but also a set of convenient high-level APIs to deal with out-of-core computations on large arrays. Dask provides data structures resembling NumPy arrays (dask.array) and pandas DataFrames (dask.dataframe) that efficiently scale to huge datasets. The core idea of Dask is to split a large array into smaller arrays (chunks).
In this recipe, we illustrate the basic principles of dask.array.
Getting started
Dask should already be installed in Anaconda, but you can always install it manually with conda install dask. You also need memory_profiler, which you can install with conda install memory_profiler.
How to do it...
1. Let's import the libraries:
import numpy as np
import dask.array as da
import memory_profiler
%load_ext memory_profiler
2. We initialize a large 10,000 x 10,000 array with random values using dask. The array is chunked into 100 smaller arrays with size 1000 x 1000:
Y = da.random.normal(size=(10000, 10000),
chunks=(1000, 1000))
Y
dask.array<da.random.normal, shape=(10000, 10000),
dtype=float64, chunksize=(1000, 1000)>
Y.shape, Y.size, Y.chunks
((10000, 10000),
100000000,
((1000, ..., 1000),
(1000, ..., 1000)))
Memory is not allocated for this huge array. Values will be computed on-the-fly at the last moment.
3. Let's say we want to compute the mean of every column:
mu = Y.mean(axis=0)
mu
dask.array<mean_agg-aggregate, shape=(10000,),
dtype=float64, chunksize=(1000,)>
This object mu is still a dask array and nothing has been computed yet.
4. We need to call the compute() method to actually launch the computation. Here, only part of the array is allocated because dask is smart enough to compute just what is necessary for the computation. Here, the 10 chunks containing the first column of the array are allocated and involved in the computation of mu[0]:
mu[0].compute()
0.011
5. Now, we profile the memory usage and time of the same computation using either NumPy or dask.array:
def f_numpy():
X = np.random.normal(size=(10000, 10000))
x = X.mean(axis=0)[0:100]
%%memit
f_numpy()
peak memory: 916.32 MiB, increment: 763.00 MiB
%%time
f_numpy()
CPU times: user 3.86 s, sys: 664 ms, total: 4.52 s
Wall time: 4.52 s
NumPy used 763 MB to allocate the entire array, and the entire process (allocation and computation) took more than 4 seconds. NumPy wasted time generating all random values and computing the mean of all columns whereas we only requested the first 100 columns.
6. Next, we use dask.array to perform the same computation:
def f_dask():
Y = da.random.normal(size=(10000, 10000),
chunks=(1000, 1000))
y = Y.mean(axis=0)[0:100].compute()
%%memit
f_dask()
peak memory: 221.42 MiB, increment: 67.64 MiB
%%time
f_dask()
CPU times: user 492 ms, sys: 12 ms, total: 504 ms
Wall time: 105 ms
This time, dask used only 67 MB and the computation lasted about 100 milliseconds.
7. We can do even better by changing the shape of the chunks. Instead of using 100 square chunks, we use 100 rectangular chunks containing 100 full columns each. The size of the chunks (10,000 elements) remains the same:
def f_dask2():
Y = da.random.normal(size=(10000, 10000),
chunks=(10000, 100))
y = Y.mean(axis=0)[0:100].compute()
%%memit
f_dask2()
peak memory: 145.60 MiB, increment: 6.93 MiB
%%time
f_dask2()
CPU times: user 48 ms, sys: 8 ms, total: 56 ms
Wall time: 57.4 ms
This is more efficient when computing per-column quantities, because only a single chunk is involved in the computation of the mean of the first 100 columns, compared to 10 chunks in the previous example. The memory usage is therefore 10 times lower here.
8. Finally, we illustrate how we can use multiple cores to perform computations on large arrays. We create a client using dask.distributed, a distributed computing library that complements dask:
from dask.distributed import Client
client = Client()
client
9. The computation represented by the Y.sum() dask array can be launch locally, or using the dask.distributed client:
Y.sum().compute()
4090.221
future = client.compute(Y.sum())
future

future.result()
4090.221
The second method scales to large clusters containing many nodes.
10. We have seen how dask.array could help us manage larger datasets in less memory. Now, we show how we can manipulate arrays that would never fit in our computer. For example, let's compute the average of a large terabyte array:
huge = da.random.uniform(
size=(1500000, 100000), chunks=(10000, 10000))
"Size in memory: %.1f GB" % (huge.nbytes / 1024 ** 3)
'Size in memory: 1117.6 GB'
from dask.diagnostics import ProgressBar
# WARNING: this will take a very long time computing
# useless values. This is for pedagogical purposes
# only.
with ProgressBar():
m = huge.mean().compute()
[## ] | 11% Completed | 1min 44.8s
The way this task is processed, chunk after chunk, can be seen on this graphic showing CPU and RAM usage as a function of time:
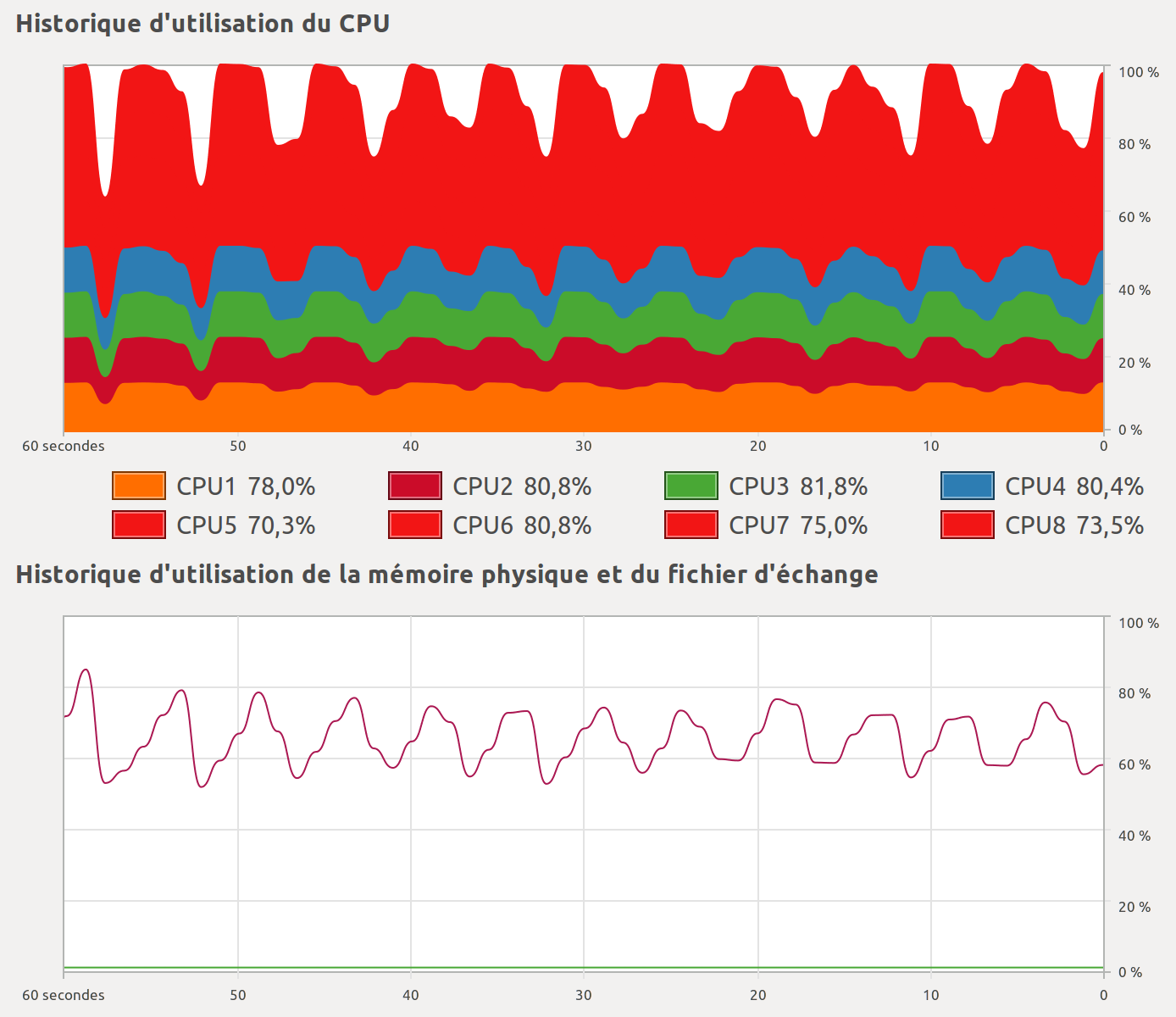
There's more...
The dask.array interface shown here is just one of the many possibilities offered by the low-level, graph-based distributed computing framework implemented in Dask. With task scheduling, a large computation is split into many smaller computations that may have complex dependencies represented by a dependency graph. A scheduler implements algorithms to execute these computations in parallel by respecting the dependencies.
Here are a few references:
- Dask documentation at https://dask.pydata.org/en/latest/index.html
- Integrate Dask with IPython at http://distributed.readthedocs.io/en/latest/ipython.html
- Dask examples at https://dask.pydata.org/en/latest/examples-tutorials.html
- Parallelizing Scientific Python with Dask, by James Crist, SciPy 2017 video tutorial at https://www.youtube.com/watch?v=mbfsog3e5DA
- Dask tutorial at https://github.com/dask/dask-tutorial/
See also
- Distributing Python code across multiple cores with IPython
- Interacting with asynchronous parallel tasks in IPython